Les organisations IT et maintenance ont toutes le même enjeu : rendre la qualité de service mesurable, prévisible et améliorable. Sans cadre, la priorisation devient subjective (« urgent »), les délais se discutent ticket après ticket, et la confiance s’érode. C’est précisément ce que cadrent SLA, SLO et OLA : trois notions complémentaires qui structurent le support informatique, l’ITSM, le ticketing helpdesk, les interventions terrain et la GMAO.
L’objectif de cet article : poser des définitions simples, clarifier les différences, puis donner des exemples concrets et des bonnes pratiques de mise en place. Les liens utiles (internes et externes) sont intégrés directement dans le texte pour un maillage optimal.
Définition du SLA
Un SLA (Service Level Agreement) est un accord de niveau de service. Il formalise un engagement entre un fournisseur de service (DSI, centre de services, prestataire) et un client (métiers, utilisateurs, entité, contrat). Un SLA répond à une question simple : quels délais et quels niveaux de service sont garantis, dans quelles conditions, et comment ils sont mesurés.
En pratique, un SLA encadre les délais de prise en charge (temps de réponse), les délais de résolution ou de rétablissement, les plages horaires (heures ouvrées, 24/7, astreinte), la priorisation (P1/P2/P3, impact × urgence) et les règles d’escalade. Selon les contextes, un SLA peut aussi inclure des mécanismes de pénalités (plus fréquent côté prestataires).
Une définition claire et “entreprise” du SLA est disponible chez IBM : Définition d’un SLA (IBM).
Pourquoi le SLA est indispensable en helpdesk et en ITSM ? Parce qu’il transforme une attente implicite en règle partagée. Sans SLA, deux demandes identiques peuvent recevoir des traitements très différents selon la charge, le contexte ou la personne qui lit le ticket. Avec un SLA, les utilisateurs comprennent ce qui est réaliste et l’équipe support gagne un cadre pour prioriser sans conflit.
Pour aller plus loin côté outil, un module de logiciel helpdesk / ticketing permet d’appliquer automatiquement des SLA par priorité, catégorie, service, ou client : Module Helpdesk & Ticketing Naofix.
Définition du SLO
Un
SLO (Service Level Objective) est un
objectif de niveau de service : une cible chiffrée appliquée à un indicateur mesurable (temps, disponibilité, latence, taux de conformité…). Là où le SLA représente une
promesse (souvent contractuelle), le SLO est un
objectif de pilotage qui aide à rendre cette promesse tenable et à améliorer la qualité dans le temps.
Dans l’approche
SRE (Site Reliability Engineering), les SLO sont centraux : ils définissent la performance attendue et servent à arbitrer les efforts entre fiabilité et évolution. Une ressource de référence est le livre SRE de Google :
Service Level Objectives (Google SRE Book).
Un point clé : un SLO bien choisi n’est pas “un KPI de plus”. C’est une cible utile, suivie régulièrement, qui guide les décisions. Exemple : si le SLA annonce une résolution sous 1 jour ouvré pour un incident majeur, un SLO interne peut viser une résolution sous 8 heures ouvrées sur 90 % des cas. Résultat : une marge existe lorsque la charge augmente, lorsqu’une dépendance bloque, ou lorsqu’un incident multiple survient.
Dans un contexte
assistant IA et
automatisation, les SLO peuvent être tirés vers le haut (meilleure qualification, tri automatique, propositions de réponses, accélération de résolution) :
Assistant IA helpdesk & GMAO Naofix.
Définition de l’OLA
Un
OLA (Operational Level Agreement) est un accord
interne entre équipes, conçu pour rendre possible l’atteinte d’un SLA. Là où le SLA est orienté “client”, l’OLA est orienté “production du service” : qui fait quoi, dans quels délais, à quel moment un ticket passe d’une équipe à une autre, et comment la communication est assurée.
L’OLA est souvent le maillon manquant : un SLA peut promettre un rétablissement en 4 heures, mais si l’équipe N2 dépend du réseau, qui dépend de l’infra, qui dépend d’un prestataire, sans engagements internes (et sans délai de réaction clair), la promesse devient fragile.
Pour les organisations structurées ITSM, les pratiques de
Service Level Management (ITIL) cadrent justement l’alignement entre engagements et capacités :
ITIL 4 – Service Level Management (AXELOS).
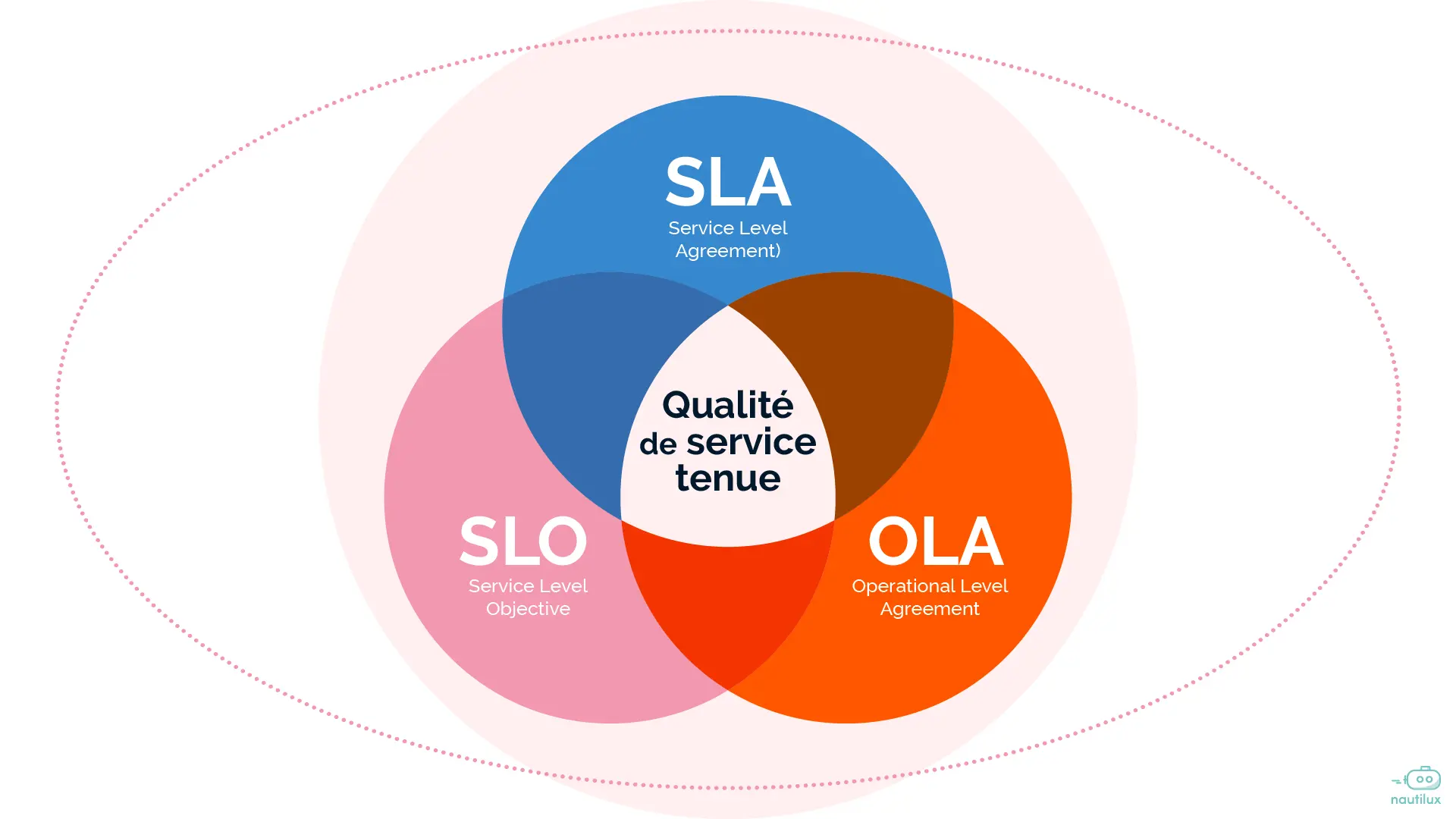
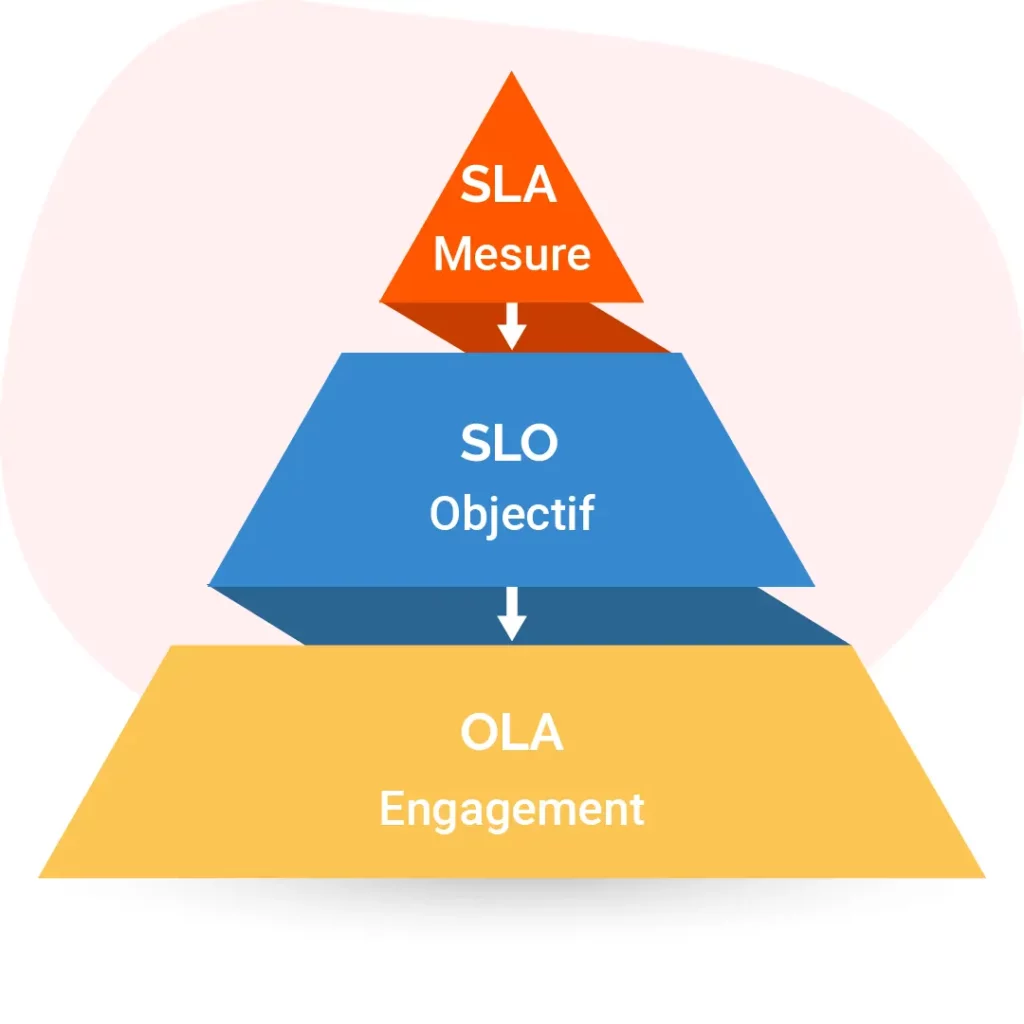
SLA vs SLO vs OLA : différences
Ces trois notions se complètent et se distinguent facilement en gardant l’intention en tête.
Le SLA est l’engagement “client / métier”. C’est la promesse de qualité de service (délais, disponibilité, couverture). Le SLO est l’objectif chiffré de pilotage : il sert à mesurer et améliorer le service pour tenir les engagements. L’OLA est l’accord interne : il organise la coopération entre équipes pour exécuter la promesse SLA.
Un repère utile : le SLA se communique aux métiers, le SLO se suit en interne sur un dashboard, l’OLA se matérialise dans les workflows (escalades, transferts, responsabilités).
Exemples concrets (Helpdesk, ITSM, GMAO)
Exemple 1 : Helpdesk - “Accès application impossible”
Dans un
logiciel helpdesk, le SLA typique se base sur la priorité. Un incident
P1 (critique) correspond à un service indisponible pour une population importante ou à un impact fort sur la production. Un
P2 (majeur) correspond à une fonctionnalité clé dégradée. Un
P3 (standard) couvre une gêne limitée. Un
P4 (mineur) concerne une demande de confort ou d’information.
Le
SLA fixe des délais de réponse et de résolution par priorité. Le
SLO pilote la performance réelle, par exemple un objectif de réduction du
MTTR (Mean Time To Repair / Restore) sur les incidents P1-P2, ou un objectif de conformité SLA au-dessus d’un seuil.
L’
OLA évite le ping-pong : il définit le délai maximal avant escalade N2, le délai de diagnostic N2, et les conditions de passage N3 (applicatif, infra, réseau). Sans OLA, les SLA échouent souvent non pas par manque de compétence, mais par manque de synchronisation.
Pour industrialiser ces règles (priorités, statuts, SLA, escalades), un outil de ticketing structuré est déterminant :
Helpdesk & Ticketing Naofix.
Exemple 2 : Incident critique - Rétablissement en 4 heures
Un SLA “rétablissement < 4 h” ne dit pas comment obtenir ce résultat. L’OLA découpe le délai global en étapes internes : qualification et collecte d’informations (N1), diagnostic initial (N2), action corrective ou contournement (N3 / infra), communication régulière (statut, ETA).
Le SLO sert à piloter la fiabilité : disponibilité mensuelle, temps de rétablissement moyen, ou taux d’incidents récurrents. Les ressources SRE insistent sur le fait qu’un bon SLO est mesurable, utile et lié à l’expérience :
Implementing SLOs (Google SRE Workbook).
Exemple 3 : Intervention terrain - GMAO et délais réalistes
Sur une panne équipement, le SLA peut promettre un “démarrage d’intervention” sous X heures. Mais la réalité dépend des pièces, de l’accès, des disponibilités, et de la qualité du diagnostic initial. C’est ici que
SLO et
OLA apportent le plus de stabilité.
Un
SLO utile peut viser, par exemple, une amélioration du taux de “bon diagnostic du premier coup” (moins de déplacements inutiles) ou une saisie systématique des comptes-rendus sous 24 heures (traçabilité, historique équipement). L’
OLA clarifie le rôle du support (pré-diagnostic), du magasin (disponibilité pièces), et de la planification (fenêtres, priorités).
Dans les bonnes pratiques d’
intervention GMAO, ce type de structuration (process, checklists, indicateurs) réduit fortement les délais et les re-traitements :
Intervention GMAO : bonnes pratiques.
Comment définir des SLA/SLO/OLA applicables et mesurables
Un cadrage efficace commence par des engagements réalistes et mesurables. Les SLA échouent souvent quand ils sont trop ambitieux, trop nombreux, ou impossibles à mesurer.
La priorité doit être définie de manière objective : une priorisation basée sur
impact × urgence évite que la “voix la plus forte” décide. Les délais doivent préciser la couverture : “4 heures” en 24/7 n’a pas la même signification qu’en heures ouvrées. Les dépendances doivent être intégrées : si une équipe dépend d’une autre, l’OLA doit répartir le temps de bout en bout, sinon la promesse est mathématiquement intenable.
Côté pilotage, des SLO bien choisis se concentrent sur quelques métriques actionnables : conformité SLA, MTTR, taux de réouverture, backlog par priorité, ou délai moyen avant première réponse. L’enjeu n’est pas d’empiler des KPI, mais de suivre ceux qui déclenchent des décisions : staffing, automatisation, standardisation, base de connaissance, ou refonte d’un workflow.
Dans un outil moderne, l’automatisation (règles, assignations, escalades, relances) et l’
assistant IA améliorent directement l’atteinte des SLO : meilleure qualification, réponses suggérées, résumés, et réduction du temps de traitement :
Assistant IA Naofix.
Pour les organisations qui souhaitent aller vers un cadre qualité, la norme
ISO/IEC 20000-1 est une référence reconnue pour les systèmes de management des services :
ISO/IEC 20000-1 (ISO).
Erreurs fréquentes sur les SLA, SLO et OLA (et comment les éviter)
Une erreur classique consiste à confondre SLA et SLO : annoncer des objectifs internes comme des garanties, ce qui crée une promesse difficile à tenir. Une autre erreur fréquente est de définir des SLA sans OLA : le client a un engagement, mais les équipes internes n’ont pas de règles de coopération, et le respect des délais dépend de l’improvisation.
Le troisième piège est la surenchère : trop de priorités, trop d’exceptions, trop d’indicateurs. Cela finit par une usine à gaz, où personne ne sait ce qui compte vraiment. Enfin, l’absence d’instrumentation (horodatage fiable, statuts clairs, règles d’escalade) rend la mesure contestable, donc le pilotage impossible.
FAQ
SLA, SLO et OLA : lequel mettre en place en premier ?
L’ordre le plus robuste consiste à partir du SLA (attente métier), puis à définir les OLA (capacité réelle des équipes et dépendances), et enfin à choisir les SLO pour piloter l’amélioration continue.
SLO et SLI : quelle différence ?
Un SLI (Service Level Indicator) est la mesure (ex. disponibilité observée, latence mesurée, délai moyen). Un SLO est la cible appliquée à cette mesure (ex. 99,9% de disponibilité). Le cadre est détaillé dans les ressources SRE : SLO (Google SRE Book).
OLA : utile uniquement pour les grandes DSI ?
L’OLA devient indispensable dès qu’un SLA dépend de plusieurs équipes (N1/N2/N3, infra, réseau, applicatif, terrain). Sans OLA, la promesse SLA repose sur des dépendances non maîtrisées.
SLA et GMAO : comment gérer pièces et contraintes terrain ?
Le SLA doit refléter la réalité (fenêtres d’intervention, disponibilité pièces, accès site). L’OLA doit intégrer magasin/stock, planification et compte-rendu. Les bonnes pratiques d’intervention réduisent l’imprévu : Bonnes pratiques intervention GMAO.
Aligner engagements, objectifs et opérations
SLA,
SLO et
OLA structurent la qualité de service au quotidien : le
SLA fixe l’engagement côté métiers, le
SLO donne un cap mesurable pour piloter et améliorer, l’
OLA organise la coopération interne qui rend la promesse atteignable. Ensemble, ils transforment un support réactif en service
prévisible,
traçable et
améliorable.
Pour relier la théorie à la pratique dans un workflow de tickets et d’interventions, l’essentiel est de centraliser priorités, SLA, escalades, automatismes et historique :
Helpdesk & Ticketing Naofix, puis d’accélérer la résolution et la standardisation avec l’
automatisation et l’
assistant IA :
Assistant IA Naofix.